At Discover, I was responsible for crafting our cloud strategy, oversaw the early delivery of that strategy, and helped ensured that development teams and their applications were aligned to that strategy. In this article, I will provide a glimpse into our hybrid cloud approach, and discuss the role Kubernetes played. I will also discuss aspects of our security principles as it applied to Kubernetes in the cloud.
Our approach to cloud consumption
When we first embarked on our journey to the cloud, we created a North Star that directed us on our approach to cloud services consumption. For us, the North Star is:
A hybrid cloud, that's fit for purpose, and allows for rapid innovation, provides consistent, common patterns for security, networking, and physical/virtual resources, that is unencumbered by legacy processes.
Our multi-year strategy is constantly evolving, but has always reflected both our short and long term goals. As a financial services company that operates internationally we knew we would have to architect for future regulations related to data privacy, data sovereignty, and the like. We understood the relative strengths of each provider and targeted them consistent with our fit for purpose principle.
Key to our hybrid cloud approach was our goal of consistency, consistency in what services we offered to our development teams and consistency in terms of how we built, deployed, ran and supported our applications. In order to achieve this goal we adopted a runtime abstraction layer over our private and public cloud providers, Kubernetes. In addition to Kubernetes we created common mechanisms to build, deploy, and interact with Kubernetes and the services offered through it.
How we use Kubernetes
The following image shows how we're using Kubernetes at Discover, with Kubernetes clusters in multiple cloud providers. These clusters are not islands unto themselves. The intention is to create a federated mesh of clusters, ensuring discovery and intelligent routing across clusters regardless of cloud provider. Additionally, a simplified experience for our development community that minimizes the degree to which they have to concern themselves with cloud provider specific nuances.
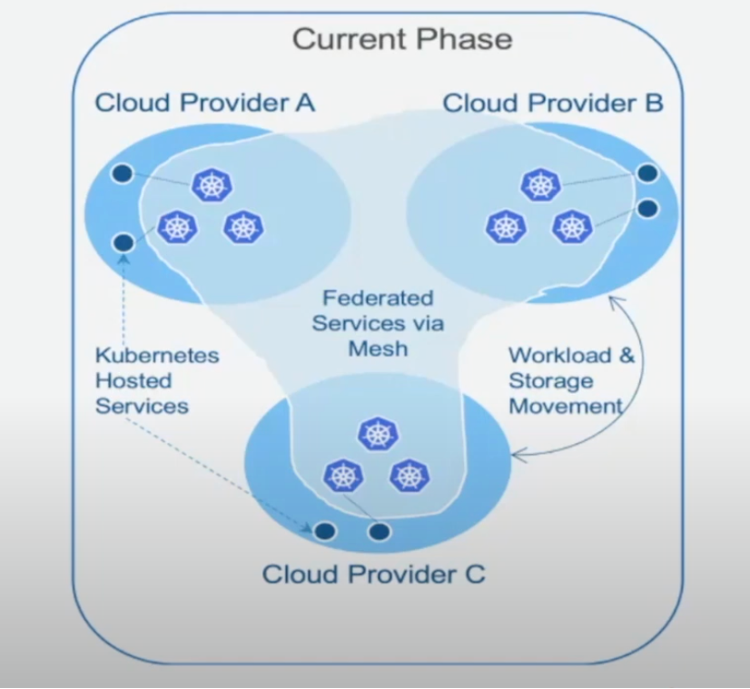
When it comes to the hundreds of cloud provider and Kubernetes-hosted services, we are very intentional in our choice of services that may create gravity around a specific cloud provider. We also take a measured approach when choosing Kubernetes hosted services as it generally has a higher operational cost to us. Regardless of where we consume services from, we always create a consistent interface for consumers.
Concentration around any specific provider represents a risk that we choose to mitigate where possible. Of course our business drivers direct our strategy, a strategy we understand may not be the most appropriate for all.
A hybrid cloud strategy is not without significant challenges however. The most notable of these challenges for a financial services company is: How do you secure applications across an ever-expanding infrastructure and services ecosystem? To start, we set some basic architectural principles that help guide us as we look to secure applications running on Kubernetes on various cloud providers.
Guiding architectural principles
Our cloud and Kubernetes guiding principles help ensure we deliver architecturally sound secure solutions across a number of domains. Let's delve into five key domains;Infrastructure, data, services, workloads, and users.
Infrastructure management
Infrastructure management refers to how Discover provisions public cloud resources such as compute, IAM, network & storage. Let’s look at the design elements that govern how we securely manage our infrastructure.
Design elements
- Everything as code, applied via automation. The only way to deploy to production environments is through auditable automated pipelines. The goal is to support a single path to production, and eliminate direct human access to environments. This helps ensures that the state of our infrastructure is always known and not subjected to direct human manipulation through cloud provider dashboards, etc.
- Single purpose, idempotent operating systems. Within our Kubernetes environments we have adopted idempotent operating systems. We never patch, we always destroy hosts requiring an update, creating new hosts with the next revision of the operating system.
- Compliance as code, no misconfiguration of cloud resources. We have compliance in the pipeline to enforce compliance at a code-level and guard against misconfigured cloud resources.
- Standardized delivery mechanisms. The mechanisms we use to deliver our applications, services and infrastructure vary per type, but they all must adhere to specific standards.
Technologies we use to enforce these principles, include:
- Kubernetes Advanced Cluster Manager includes policy-driven cluster lifecycle management. These policies are well defined and consistently applied ensuring that all our Kubernetes clusters don't diverge from the expected state.
- Kubernetes & Cloud Native services delivered via standardized operators: Kubernetes operators are a standard way to codify standard operations. We use them to automate certain processes and reduce human interaction with processes.
- Continuous Compliance Engines integrated into pipelines and operators. We have compliance engines looking at all our public and private cloud spaces, built into pipelines. This lets us proactively ensure continuous compliance in those environments.
- Kubernetes worker node taints, strict isolation policies. Technology that supports strict isolation policies helps us ensure that we create specific infrastructure for specific workloads.
Data management
Data is the most critical part of our business. Any compromise of data is intolerable and detrimental to any company, but especially to one such as ours. Its imperative that we know where our data is flowing, where it is stored, and who or what has access to it. We use the following design elements in our hybrid cloud architectures to secure our data.
Design elements
- Use two forms of obfuscation on sensitive data (PII/PCI) at rest. Public cloud providers allow for encryption of data managed by their services, either through keys they provide or keys consumers can provide (the Discover standard). Discover leverages those cloud provider capabilities but don't view them as sufficient alone. We also require another form of obfuscation, such as tokenization or encryption of data that is not provided by the cloud providers. Defense in depth is applied in general but is especially critical here.
- All data in transit must be secured via transport level security. Regardless of the protocols in place, having transport level security (TLS) is non-negotiable.
- All data transfers between clouds must traverse a clearinghouse where it’s inspected and secured through common, approved patterns. As data is moved between clouds (private or public), understanding what data is moving and where it’s going is imperative to securing it. Data that’s moving from one cloud to another cloud must go through a clearinghouse where it’s interrogated by specific technology and tokenized or encrypted.
- Any in clear processing must be done in memory with physical and logical isolation. Handling of sensitive data must be appropriately isolated and done in memory. Sometimes this is governed by outside standards, e.g. PCI.
Technologies we use to enforce these principles, include:
- Data loss prevention tools for detection and scrubbing. Using tools that detect and scrub sensitive data is an important step in protecting data. Most public cloud providers offer these services that can be used to augment existing solutions.
- Tokenization and encryption tools. Tokenization and encryption is critical to securing data at rest or in transit, so we invest in tools that enable encryption.
- Secure File transfer platform with full audit capabilities. We want to know when people are moving data to the cloud or between clouds and be able to audit data movement at any time.
- Secure, network isolated landing zones via declarative network policy, taints, and toleration. There are a lot of providers in this space, but this technology is critical to creating isolation. Micro-segmentation has been a design point since our first Kubernetes deployments.
Service management
Services refers to the applications and the supporting services (Restful, GraphQL) that may be distributed across multiple cloud providers. Let’s look at the design elements that govern how we manage our services.
Design elements
- Multiple controls at trust boundaries. Our cloud footprint including the services we consume are spread across the globe, with traffic flowing across different trust boundaries. These boundaries can be at the service within a Kubernetes pod, at the Kubernetes cluster level, or where traffic enters or leaves a given cloud provider.Discover always adheres to our defense in depth philosophy and as such we always implement multiple control points.
- Service registration with service providers and consumer relationships. Understanding all our endpoints, who owns the endpoint and who is calling it must be known. Relationships must be established and secured.
- Service trust via token/certificates issued by trusted entities. Trust between two entities is always required, with the ultimate solution depending on whats supported by consumers and producers.
- Service isolation for APIs handling sensitive information. This isn’t exclusive from the data conversation, but we must isolate any service handling sensitive information. We have strategies to create secure enclaves for these workloads.
Technologies we use to enforce these principles, include:
- Layer 3 host and pod network ingress/egress policies with Layer 7 API Authentication. Discover employs a combination of layer 3 and layer 7 controls. Even if there’s a breakdown at the network layer, service point authentication and the contract enforced by providers ensures there is no unwarranted access. API gateways, network policy plugins supporting micro-segmentation are a few of the technologies we leverage.
- API Governance Portal with service registration, relationship identifications and token issuance. Knowledge of what services are being introduced into our environments. An API Governance Portal with a strict registration process, relationship identification, and token issuance to each of our services is mandatory.
- Secure provisioning of Token/Certificate from trusted providers. Secure issuance patterns via pipelines, Kubernetes sidecars, etc. Identities associated with running processes allow for the automated, transparent secrets injection.
Workload management
We use the following design elements to help manage where workloads are deployed across our clouds.
Design elements
- Mutation of workloads with metadata based on application portfolios. Discover mandates the we know all the components constituting a given application. In order to do this we mutate application deployments with metadata that allow us to place workloads appropriately.
- Physical and logical isolation of workloads based on application characteristics. PCI handlers, builds, research and development activities are examples of characteristics that would alter workload placements. Once we recognize who is deploying the workload and the characteristics of their application, we segment the workloads. Those segments could be logical or physical isolation.
- Rejection of workloads that don’t align to application portfolio metadata or label taxonomy. If a workload is not aligned to our label taxonomy and we don’t understand everything about that workload, then we will prevent its deployment.
Technologies we use to enforce these principles, include:
- Application Portfolio Management for application metadata. Application Portfolio Management platforms are a critical piece here. All applications must accurately reflect their applications and components.
- Kubernetes Mutating and Validating Admission Controllers to apply application metadata. We use pipelines, mutating and validating admission controllers to apply & validate application metadata. We don't allow applications and teams to provide their own metadata. We control every aspect of how their metadata is crafted and ensure that we’re applying the metadata as it’s coming from the APM.
- Kubernetes Taints and Tolerations for workload isolation based on security and compliance requirements. We want certain nodes to repel certain workloads, and we also want the ability to ensure that we're placing certain workloads on certain nodes.
- Declarative Kubernetes Network Policies for micro-segmentation. Network policy for North-South and East-West flows ensure that we control access to sensitive workloads, e.g. endpoints that handle PCI data.
User management
User management refers to users who are interacting with our cloud services.
Design elements
- Access to environments must be protected with multiple authentication factors.Having more than one authentication factor increases security and is required for all cloud environments.
- Kubernetes platform administrators shouldn’t have access to application secrets. Kubernetes platform administrator should not have access to application secrets, so we need a bifurcation of administrative rights where secrets are managed external to the Kubernetes platform.
- All administrative activities only through call after access with short- lived tokens. Call alter is required where elevated access is required. No one has standing access and access to hosts through things like SSH are not allowed by default. Access is also short-lived and must be requested for specific purposes. The approval process must be fully audited.
- Highly sensitive workloads must run in restricted environments with no human access. For highly sensitive workloads, our goal is to have zero human interaction. If human interaction happens, there are stringent audit procedures in place to understand exactly who touched what and why.
Technologies we use to enforce these principles, include:
- Multi-factor authentication providers. There are numerous good multi-factor authentication providers.
- Externalization of secrets from Kubernetes with secrets vault providers. Our view is that Kubernetes secrets aren’t secrets, so we externalize them with external vault providers.
- Short-lived tokens issued and tracked via secrets vault providers with full integration to SIEM (Security Information Event Monitoring) tools. Integration with SIEM tools enables us to detect and prevent any threats in real-time.
- Public cloud providers account segregation controlled with coarser grained security groups and fine-grained Kubernetes network polices, with break glass user access only. Users, what they can access and from where is highly controlled. Network isolation controls along with secure token generation are key controls here.
Conclusion
We have just scratched the surface on the topic of security, but hopefully, this article has helped you understand some of critical design principles we put into practice here at Discover. Ultimately, your requirements will drive your architectures. The controls discussed here represent a combination of good hygiene as well as requirements necessary in highly regulated verticals.



